UTF에 대해서
UTF란 유니코드 변환 형식(Unicode Transformation Format) 인코딩을 의미하는데,
여기서 인코딩은 어떠한 정보, 데이터를 다른 형식으로 변환시키는 과정을 뜻한다. 대표적인 UTF방식으로 UTF-8과 16이 존재한다.
유니코드란?
컴퓨터는 0과 1의 이진법만 이해하는데, 사람은 익히기만 한다면 그와 달리 매우 많은 언어를 구사할 수 있다.
따라서 인간의 언어(자연어)를 컴퓨터(기계어)가 이해하기 위해서는 중개자가 필요하다.
그 중개자 역할을 하는 것이 유니코드이다.
어떻게 이루어지는가?
예를 들어 유니코드를 UTF-8로 인코딩을 한다고 가정해보자.
인코딩 규칙은 다음과 같다.
1. 1개 바이트를 사용하는 경우
- 이 경우에는 가장 큰 비트에 0을 할당하고, 나머지 7비트에 기존의 아스키 코드를 할당한다.
2. 사용하는 바이트가 2개가 넘는 경우
- 첫 바이트에는 몇 바이트를 사용하는지 알려주는 비트를 먼저 넣는다.
- 예를 들어 2바이트 (110), 3바이트 (1110), 4바이트 (11110)처럼 말이다.
- 나머지 바이트에는 여러 바이트에서 연결되었음을 알리는 비트를 넣는다. 2바이트와는 겹치지 않기 위해서 10이라는 비트를 포함한다.
| 유니코드 | utf-8로 저장하는 값 | ||||||
| 자릿수 | 코드값 범위 | 1바이트 | 2바이트 | 3바이트 | 4바이트 | 5바이트 | 6바이트 |
| 00~07비트 | 0 ~ 0x7F | 0xxxxxxx | |||||
| 08~11비트 | 0x80~ 0x7FF | 110xxxxx | 10xxxxxx | ||||
| 12~16비트 | 0x800 ~ 0xFFFF | 1110xxxx | 10xxxxxx | ||||
| 17~21비트 | 0x10000 ~ 0x1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 22~26비트 | 미사용 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 27~31비트 | 미사용 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
유니코드의 문자들을 UTF-8형식으로 변환한다면 다음처럼 변환될 것이다.
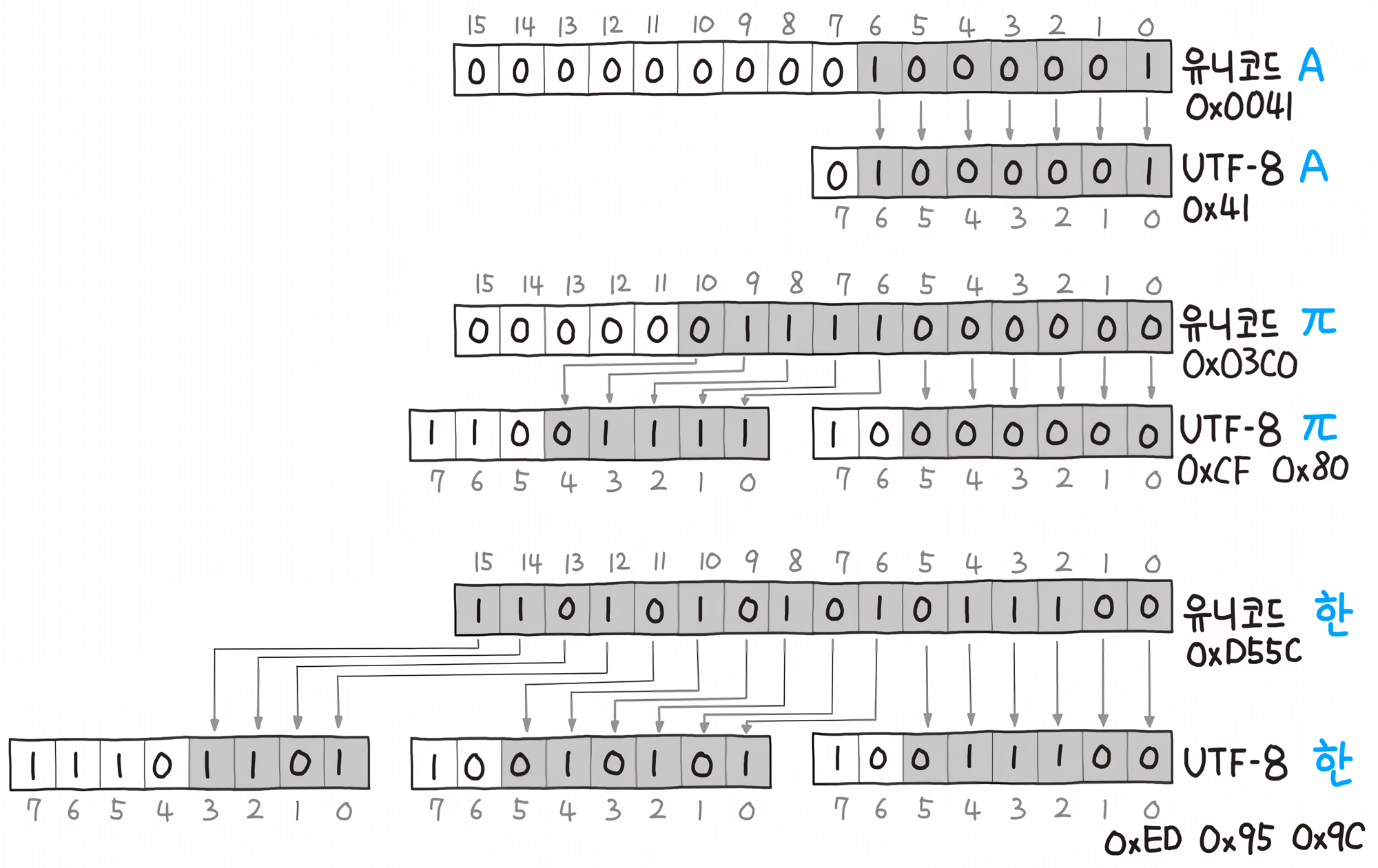
UTF - 8과 16의 차이점
UTF 16의 경우 8비트와 약간의 차이점을 갖고 있는데, 문자 하나를 표현하기 위한 필요 bit의 크기가 16바이트가 필요하다는 점과 문자 하나를 표현하기 위한 byte범위의 경우 UTF-8이 1~4바이트 만으로 가능하다면 2~4바이트가 필요하다는 점이다. 그렇다면 필요 없는것 아닌가 싶겠지만, UTF-8의 경우 저장공간 효율성과 아스키 코드와의 호환에 중점을 뒀다면, UTF-16의 경우 동아시아 언어와 같은 다국어 문자를 빠르고 효율적으로 처리하기 위해 설계되었다는 차이점이 있다.
'Programming > 기타' 카테고리의 다른 글
| 비트 연산 (0) | 2025.01.08 |
|---|---|
| 구조체 패딩 (0) | 2024.12.30 |
| 워치독 타이머(Watchdog Timer) (0) | 2024.12.15 |
| 소프트웨어의 정의와 특성 (1) | 2024.12.08 |
| 인터페이스와 추상클래스 (0) | 2024.12.08 |